转自 CAAI会员中心
摘 要
当前我们虽已身处大数据时代,但代价高昂、不易获取的标记数据依旧是机器学习发展的瓶颈。相比而言,无标记数据廉价且易获取,因此,如何高效利用它们一直是学者们关注的焦点。最近,一种无监督学习的新范式——自监督学习已开始受到广泛关注,其旨在减少对大量标记/ 注释数据的需求。为此本文围绕该学习范式作出简要回顾及展望,并力图从一个新的视角来考察该范式,以期为后续研究提供一些洞察。
关 键 字
机器学习;自监督学习;多视图学习;数据增广

0 引言
目前机器学习技术已获得了令人印象深刻的进展,尤其是深度学习已在计算机视觉和自然语言处理等多个领域取得了突破。然而,它仍存在许多不足。例如,当前许多机器学习技术(如分类)的成功大都处在一个封闭、静态的环境下,即训练数据和测试数据来自相同的标记和特征空间。但更实际的场景通常是动态、开放和非平稳的,如无人驾驶、医疗诊断等。在此类场景下,一些意外情形常会出现,致使这些现有模型往往难以奏效,甚至变得无用。为迎接这些挑战,学界开始探索诸如安全的AI(Safe AI-Open World/Dynamic Learning)、终身/连续/预测/元学习(Lifelong/Continual/Predictive/ Meta Learning)、迁移学习和域适应(Transfer Learning&Domain Adaptation)等的相关研究,由此产生出了众多成果。
与此同时,另一个面临的严重局限是,当前学得的强大模型(特别是深度模型)往往需要大量的带有注释/标记的训练示例,而在众多实际任务中,收集这样的数据既耗时又昂贵。在当前大数据背景下,相比代价高昂的标记数据,无标记数据廉价且易获取。另一方面,正如Yoshua Benjio在MLSS 2014上所指出的那样,对于成功的机器学习,好的特征是其本质所在。那么如何利用这些无标记数据学习好的特征?常规的手段首选是采用无监督学习。然而,由于监督信号的缺乏,其所学特征通常难以保证判别性。近年来,一种根据数据的某些属性自动生成监督信号来引导特征学习的新范式——自监督学习(Self-Supervised Learning)渐受关注。对此,Yann LeCun在2018国际人工智能联合会议(IJCAI)的主题演讲中特别指出:机器学习的未来不会是监督学习,也不会纯粹是强化学习,它更应该是(包含了深度模块 的)自监督学习。其关键想法就是利用所设计的自监督信号帮助学得判别性的特征。因此,尽管目前发展出了大量针对新场景的机器学习方法,然而鉴于自监督学习范式的重要性和广泛的可用性,本文更多地关注自监督学习的最新进展,尝试从一个全新的角度来重新审视自监督学习的实质, 由此为后续研究提供若干洞察。
1 自监督学习
1.1 何为自监督学习
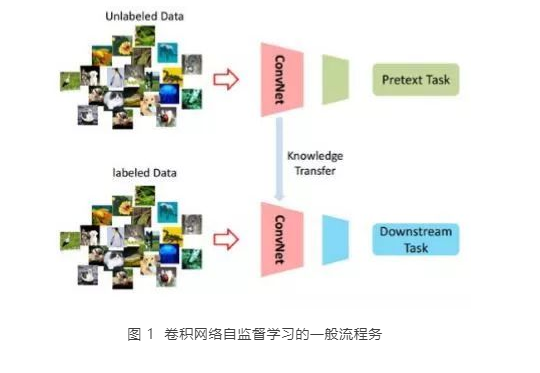
自监督学习(Self-Supervised Learning)是一种介于无监督和监督学习之间的一种新范式,旨在减少对大量带注释数据的挑战性需求。它通过定义无注释(annotation-free)的前置任务(pretext task),为特征学习提供代理监督信号。图1展示了卷积网络(ConvNet)自监督学习的一般流程,为克服无监督特征学习的不足,它在训练阶段通过为ConvNet设计一个附有伪标记的前置任务(pretext task)进行求解。因此自监督学习的关键在于如何在前置任中引入伪标记,手段之一是根据数据的某些属性自动生成。在前置任务训练完成后,可将学得的特征作为已训练的模型进一步迁移到下游任务(downstream tasks),使其获得更好的解的起点。
1.2 常用的前置任务
针对ConvNet前置任务的训练,已提出了许多无需人工标注的方法,这些方法使用各种线索和代理任务,包括前景对象分割(foreground object segmentation)、 图像修补(image inpainting)、聚类(clustering)、图像着色(image colorization)、拼图游戏(jigsaw puzzles)、噪声作为目标(noise-as-targets)、预测编码(predicting coding)和预测旋转(predicting rotation)等。此外,也有许多方法使用额外的信息来学习特征(比如对于视频,其内含的时间信息用作自监督信息)。目前典型的前置任务有基于时间上下文(temporalcontext)、基于时空线索(spatio-temporal cues)、基于光流(optical-flow)、基于未来帧合成(futureframe synthesis)、基于视频的音频预测(audio prediction from video)、基于音频-视频对齐 (audio-video alignment)信息、基于自我运动估计 (ego-motion estimation),以及采用高阶时间相干性的慢特征分析(slow feature analysis with higher order temporal coherence)等。更多细节,参见最近自监督学习的综述。
1.3 广泛的应用场景
当前自监督学习被广泛用于语义分割、目标检测、图像分类和人体动作识别等。同时,作为一种辅助性的学习任务,最近已被扩展到域适配(Domain Adaptation)、少样本或零样本学习(Few/Zero-shot Learning)、分布外检测(Out-ofDistribution Detection) 、生成对抗网络和图卷积网络等学习场景。
2 对自监督学习的重新审视
最近有学者分别从卷积网络和鲁棒学习的角度剖析了自监督学习的内含,对此简要梳理如下。
2.1 卷积网络 (CNN) 的角度
Kolesnikov等学者通过研究多种网络结构与 多种自监督学习前置任务的组合得到以下启发性的经验结论。
(1)与监督学习不同,自监督学习任务的 性能显著依赖于所使用的卷积网络(CNN)的结构,例如,对于rotation预测,RevNet50性能最好;但是对于jigsaw预测,ResNet50v1性能最好。
(2)相比于AlexNet(在网络末端特征质量会下降),具有skip-connections结构的网络(如ResNet),高层特征的性能不会下降。
(3)增加CNN模型中滤波器的数量,可显著提高所学特征的质量。
(4)所训练线性模型的评估过程非常依赖学习率的调整策略。另外,作者实验验证了前置任务更好的性能,并不总能转化为下游任务更好的特征表示。
2.2 鲁棒学习的角度
Hendrycks等学者从鲁棒学习的角度重新剖析了自监督学习。他们发现自监督学习可以通过多种方式提高鲁棒性,包括对抗样本的鲁棒性、标签损坏(label corruption)的鲁棒性和常见输入损坏(common input corruptions)的鲁棒性等。此外,自监督学习在困难的、近分布的(neardistribution)异常点的分布外检测中也大有益处,以至于超过了完全监督方法的性能。这些结果显示了自监督学习在提高鲁棒性和不确定性估计方面的前景,同时也为将来自监督学习的研究提供了新的评估方式。
3 多视图视角——我们的视角
通过引入自监督标签/信号来为下游任务学得有效的特征表示,自监督学习确实显著地提高了下游任务的学习性能。但是现阶段如何设计前置任务,或如何进一步提高自监督学习方法的性能,仍是一个很大的问题。据我们所知,当前仍缺乏相关理论对其设计进行指导。
事实上,从多视图角度看,自监督学习中引入的自监督信号实质上是对原始数据进行了各种变换(如旋转、着色和拼图等)从而产生多个变换数据(可视为多个视图数据),这恰好落入我们早期提出的单视图的多视图学习框架。换句话说,自监督学习的本质就是对原数据进行多视角的数据增广,这不同于传统的数据增广,因为它考虑到了所附的自监督信号。从该视角来看,我们相信在理论上能借鉴已有的多视图学习理论,弥补自监督学习理论的缺乏,并对其进一步拓展。
(1)解释现有自监督任务(如图像修补、着色)在某些学习任务性能不佳的原因,即这些变换实际产生了相对原数据信息缺失的不完全视图数据,从而对某些下游任务的执行造成干扰。因此,如何聚合这些有缺陷视图数据提升自监督学习值得深入研究。
(2)产生更加多样性的自监督信号,比如通过变换合成,可对数据示例作变换的复合/嵌 套/层次等运算。
(3)除了在数据层面,还可在模型层面(如扰动模型)、优化算法层面、任务层面等进行自监督学习的开拓;
(4)针对多层网络,不仅在其输入层,而且对其各内层进行自监督信息的生成等。对上述几点,我们正在进行初步探索。
反过来看,自监督学习充分利用自监督信号 (从多视图视角看就是视图标记),同样启发我们探索多视图学习中视图标记的利用。当前几乎所有多视图学习都忽略了视图标记这一附带信息,这值得进一步深入讨论。另外,它也为产生同构的多视图数据提供了一种手段。
4 结束语
面对当前的挑战,众多针对新场景的机器学习算法研究已取得突破性进展,然而限于文章有限的篇幅和本人能力的局限,本文主要关注自监督学习,并尝试从一个新的视角——多视图视角来重新审视它,由此为其后续研究提供一些思路。
陈松灿:南京航空航天大学教授、CAAI机器学习专委会主任、江苏省人工智能学会常务理事长